2.3 F-BFT Consensus
2.3.1 The BFT Consensus Model
The Consensus is a special mechanism to ensure the integrity and security of data in a distributed network. There is advanced mathematical apparatus (for instance, the FLP theorem, see 2.1.1) that clearly demonstrates that solving problems of such integrity requires several compromises. Within the framework of DGT, consensus is understood as the ability of the network to withstand CFT (Crash Fault Tolerance) and BFT (Byzantine Fault Tolerance) attacks. The main principles of such protections include:
Attacks are understood as the probability of problem occurrence in relation to the main goal of information security: the protection of confidentiality, integrity, and data availability.
The implementation of attacks is inextricably linked with the Adversary Model: action scenarios of an attacker or other subject that violates the aforementioned properties of information security. Scenarios define a set of specific actions aimed at system vulnerabilities. Each set of scenarios associated with a particular vulnerability is called an attack vector. The total set of vulnerabilities (and therefore the sum of probabilities of the attack vectors) is also called the Attack Surface. The task of information security, and therefore the main task of the consensus, is to reduce the attack surface.
Distributed decentralized systems have many points of vulnerability or attack vectors, which can be divided into three categories:
General attacks on information security. These include attacks on clients, cryptography, network attacks (ex. DDOS)
CFT-attacks aimed at violating fault tolerance in case of failures, i.e., the ability to ensure data integrity when one or more nodes is unavailable. The main emphasis of such attacks is on the distribution
BFT-attacks that include complex malicious actions to violate the integrity and confidentiality of data, considering the decentralization of the system
Some attacks give birth to others, so a full analysis requires analysis of all types of attacks. To simplify, the issue of consensus tends to be focused on CFT and BFT, including general attacks that act as preparatory or accompanying actions. Basic BFT attacks include:
51% Attack (consensus hijacking): an attacker tries to take over the network by controlling more than half of the nodes to achieve more complex goals, such as double spending or completely changing the registry
Double Spending: data changes that allow you to spend the same funds twice on the network. It can be carried out in two main variations: Race Attack (two or more transactions start at the same time in the hope that the distributed system will not have time to synchronize); or Finey Attack (a block is prepared in advance that cancels the previous transaction and allows you to re-conduct the transaction on already debited funds)
Sybil Attack: creating fake nodes that generate fake transactions
Eclipse Attack: an attack like the Sibyl attack, which consists of isolating the victim node, which then interacts with the fake network
The consensus mechanism is a data processing algorithm directly related to the architecture of the system under consideration, which guarantees three basic properties for ongoing transactions:
Termination - the process of considering a transaction must be completed in one way or another (including through rejecting the transaction)
Integrity - the processes of considering the same transactions by different nodes should come up with the same values / results
Agreement - the value / result agreed between the nodes should be stored as the only possible true one
Distributed decentralized systems (like DGT) work asynchronously, implying a refusal from immediate transaction completion. The client sends the transaction and immediately receives a receipt for its registration; however, the transaction takes some time to complete and requires a second call to the system to get the result.
According to the FLP Impossibility theorem (see 2.1.1), a determinate algorithm (i.e., that always produces one consistent result) is impossible in a fully asynchronous distributed network, in which at least one process may crash. In other words, the simultaneous achievement of fault tolerance, liveness, and safety is impossible. However, with a probabilistic approach, at least two of the listed properties can be achieved simultaneously, such as liveness and fault tolerance.
There is also a heuristic CAP Theorem (Brewer’s Theorem) that states that out of the three possible states of the system (C - consistency, A - availability, P - partition tolerance), only two can be reached at the same time. In particular, there exist the so-called BASE architectures that oppose ACID systems [1] (standard relational databases) and guarantee a Basically Available, Soft-state, Eventually consistent state. It is described through basic availability, unstable state, and consistency that is eventually reached.
Common consensus systems can be divided into several classes (see [29]). These include BFT-Compliant algorithms (based on PBFT or RBFT voting), Proof-of-X consensuses (based on proving some advantages, such as computational power for Proof-of-Work), hybrid or alternative consensuses (ex. DAG-based consensuses like Hedera, Hashgraph, IOTA), as well as CFT-consensuses (RAFT, Zabb). Even though the full mathematical description of the F-BFT consensus used by DGT is beyond the scope of this documentation (see [30]), let’s review its main architectural features:
F-BFT is a generalization of the PBFT consensus onto a multi-level hierarchical network, in which nodes form clusters with variable leaders.
It is assumed that some nodes belong to private segments and undergo an identification procedure when joining the network (this excludes attacks like 51%)
A transaction generated by the client enters the primary node (PRIMARY) and is validated within the cluster. As part of the voting, each of the cluster nodes performs the voting procedure:
Verification (formal verification of the correctness of the transaction and client signatures)
Validation (checking the stack of rules directly related to a specific family of transactions)
Signing (the transaction if it is approved and then passing the results to the current leader)
The main behaviour of the cluster when voting on a transaction is based on the general logic of processing / phases (pre-prepare, prepare, commit) with consideration for:
If the number of votes corresponds to the established consensus threshold (depending on the network configuration, this threshold may be 51% or (2f +1) of “honest” nodes from the cluster with (3f +1) nodes), then the transaction (or rather a package of transactions, see 2.4.1) is submitted for arbitration.
Arbitrators are special nodes that form a ring of arbitrators (that is a specialized virtual cluster) that is located outside of the original cluster and rechecks transactions to complete the final commit - the insertion of the transaction into the ledger. The general arbitration mechanism is set out below.
Arbitration [2] is an additional mechanism that guarantees the validity of transactions outside the cluster. This solution provides a guarantee to the network against insertions of transactions when an entire cluster has been compromised, while also ensuring data integrity across the entire network:
For example, in case of weak network connection (voting occurs in the cluster connected with the network through many intermediate permalinks), additional confirmation of the transaction integrity and correctness by an arbitrator serves to improve the quality of information and the speed of its distribution
In case of a “double spending” attack, the network’s common type of transactions made be attacked by an attempt to spend more than that the account owns. Arbitration reduces the probability of this occurring due to the difference between the network’s synchronization time and the voting time in the cluster.
The following algorithm represents the general schematics of arbitration [3] :
According to the given conditions, a list of potential arbitrators is formed in the network for each family of transactions. Such arbitrators must belong in different clusters, have a certain level of SLA, and not necessarily be current “leaders”. In the limiting case, such arbitrators are static (a ring of arbitrators).
When voting is conducted on a transaction of a given type, an arbitrator is randomly selected from a given set of arbitrators, after which the transaction (package of transactions) is transferred to him for arbitration
An arbitrator validates a transaction, after which they add it into DAG (according to the support vertex - the “nest”)
Next, the DAG is synchronized out from the arbitrator through permalinks.
The proposed F-BFT consensus allows for effectively dealing with common BFT attacks and ensuring data integrity, provided that the network is correctly formed and there is a required number of “honest” nodes in the cluster. The main advantages of using the F-BFT consensus include:
Overcoming the limitations of the PBFT consensus in terms of network scaling
High transaction speed
No energy costs (such as for Proof-of-Work) for mining and low computational cost of transactions
Consideration for the nuances of hybrid networks and the ability to work with transactions of various types (families of transactions)
2.3.2 General Trust Environment and Notary Nodes
An important component of the DGT platform is the support of the full cycle of data about tokenized objects. Data processing in public blockchain networks focuses only on internal processing, the on-chain operations. Off-chain operations, as well as verifying information from the real physical world are both ignored. Authentication and authorization issues are solved using a pair of keys - private and public, the comparison of which is determined by a signature. This circumstance has several consequences:
Lack of unique identification for subjects (system actors) and objects: practically any real object may have an unlimited number of associated key pairs
The inability to restore accounts and cancel operations.
The lack of reliable information about real physical processes and objects, including those whose digital copy is reflected in the network.
DGT is based on the following technical assumptions:
Storing confidential data within the ledger is not desirable since such information may be disclosed due to the limitations of cryptography and the general ideology of decentralized networks [4].
The mechanism for verifying confidential data should be embedded into the transaction mechanism and should interact with the normal BFT consensus rules (see 2.3.1).
Reliable verification of information lying outside the network can be done using the Zero-Knowledge-Proof (ZKP) approach. The essence of this process is to prove the possession of confidential information without disclosing it. The test scheme below is a simplified version of the Arthur-Merlin Protocol and its full version is still being developed by DGT.
Notary Nodes are a special node type that forms the foundation of expanding the environment of trust of the DGT platform. The objective of these nodes is to check, identify, and store confidential information in the network. Notary node architecture features:
Notary nodes perform a dual role: they are included in the general DGT network exclusively in private segments, (see 2.2.2), have access to a common registry (DAG), but also have additional business logic responsible for off-chain data checks
Each notary node has a separate key-value storage for sensitive data (Verifiable Credentials) around subjects and objects involved in the processing (hereinafter referred to as VCDB). VCDB is a micro ledger used to validate certain facts about subjects and objects.
Notary nodes form a separate network (virtual cluster), which has the objective to synchronize VCDB. Since the nodes are in protected segments, their synchronization is ensured by the CFT consensus (RAFT).
Confidential data enters the VCDB storage through direct user interaction with the Notary services (using User-Agent software), which includes the receipt of a decentralized ID (DID), as well as registering additional confidential data (VC). In this case, DID is a number issued during the identification process (see 2.3.3). In essence, this is verification of a special type of VC subject/object.
Throughout the process of transactions of a certain family type (see 2.4), the transaction processors refer to special notary API for verify certain information, while implementing an interactive ZKP process.
Immediate data that is checked within the transaction is a set of roles (for example, those that allow to place a limit on the amount of transaction, reject the operation, check the validity of the object’s properties, such as its existence). Roles are numeric flags that bind the transaction type and VC. They are unavailable within the transaction itself but are available to nodes of the Notary type.
A bird’s eye view of the interaction with notary nodes is presented in the schema below. The process is divided into two parts: (1) receiving DID and storing VC; (2) performing checks in the transaction process.
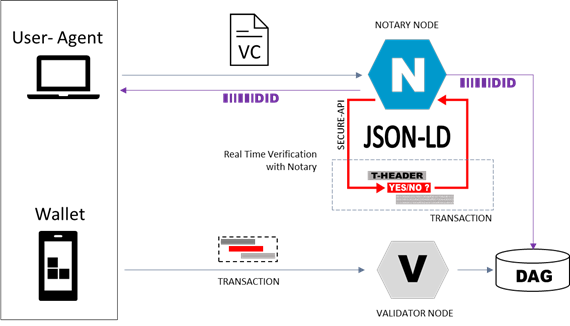
The use of notaries within the system allows for complex transactions with real-time verification of the conditions that allow for the transaction to be carried out. The current version of DGT (Matagami) has the following limitations:
All notaries have access to general information of a confidential nature (later there will be a division between this information and registering access to it from the subject-holder)
The direct use of notary nodes is limited to several transaction families.
The figure below presents the scheme of interacting with notary nodes for a DEC payment transaction (see 2.7.3).

2.3.3 Decentralized Identification
Verifying transactions like exchanging digital objects for tokens, transferring tokens, and emitting them requires additional information within the framework of the generalized tokenization model (see 2.7.1):
Does the tokenized object really exist and is it unique?
Does this user have the right to the corresponding operation with tokens?
Does this object have certain properties involved in this transaction?
Notary nodes are used to clarify this information. The central concept of linking information to a particular object is in essence the process of identification, which involves establishing the identity of the unknown object as a known one, i.e., the proof of its existence and its uniqueness. The features of the identification process are as follows:
Identification of any given entity is done through the properties / attributes of this entity. The objective of identification is to have proof that for a given set of entities (domain area), the identified object exists and is unique, as in there are no other objects with the same set of attributes.
The entity may possess many attributes, but only some of it may be used to identify a unique object. Such attributes are called quasi-identifiers. Frequently, one entity may have several sets of quasi-identifiers, but identification is usually done through one main set.
Based on the results of identification in computational systems, objects receive a unique numeric identifier, which is also called the object’s pseudonym. Such pseudonyms are unique within the domain area and each pseudonym covers a group of quasi-identifiers.
The entity’s attributes that are not quasi-identifiers are confidential information that directly impact the ability to operate with the object and execute transactions of certain types. For confidentiality purposes (as well as for hiding personal data, see 2.3.4), it is necessary to separate the storage of confidential data from open data, as well as to provide interoperability between different security borders for processing information.
The complete identification process includes the identification itself (the process of selecting the objects and proving their uniqueness), verification (checking the attributes and verifying the right to own this identifier - authentication), authorization (the ability to perform certain actions / transactions with the given identifier).
The decentralized identification process has the following features:
The actions of registering and managing identification is available to several participants.
The process of using identifiers is under the control of the identification subject, its owner.
Using VC attributes for the authorization process is separate from the VC registration process and authentication itself.
In terms of public key infrastructure (PKI), one DID may be associated with several public keys and methods of verifying attributes.

In a hybrid network environment (see 2.2.2) identifier management walls to the notary nodes. DGT uses the following process:
A network user receives a decentralized identifier (DID) while interacting with one of the notary nodes off-chain.
When creating DID, a notary node stores attributes in an encrypted form in the VCDB micro-ledger, while DID is stored as an anchor inside the DAG ledger.
The authentication process is carried out using the DID, the public keys associated with it, and the signature with the private keys known only to the user.
The DID is accessed from the inside of the corresponding transaction families being processed through calls to the secure APIs of notary nodes and obtainment of a role (authorization process).
The generalized identification process for networks with the H-Net architecture is shown in the figure below.

The proposed scheme addresses the following risks:
Identity theft (spoofing). As part of the attack, the attacker gains access to the partial ID. The threat is offset by a secret-sharing scheme and ID verification by validators.
Data tampering. As part of the attack, the attacker intercepts transactions and changes their content. The threat is addressed by encrypting all traffic between the subject and nodes. By default, the attacker does not have access to the keys.
Node substitution (Sybil Attack). Normal transactions are validated as part of reaching consensus. Trust Provider oracle nodes are most vulnerable to these attacks as they receive data from the outside. The H-Net architecture permits oracle nodes exclusively in consortium-based or private network segments, which defends from substitution.
Careless consent to actions (explicit consent). This threat refers to a situation in which the user transfers rights or data outside of the identification procedure. The threat is minimized by the authentication procedure, which excludes access to authorization methods until its results are obtained.
Data corruption by Trust Providers (oracle problems). One of the most significant problems is the supply of off-chain data through the Trust Providers (notaries) interface. Even though direct substitution is resolved by encapsulating oracles through arbitrator node interfaces (in terms of SAML - circle of trust, CoT), this cannot exclude a significant distortion of the data itself.
Selective disclosure. Such threats are mitigated by querying through the Proxy ID, which means users cannot select arbitrary attributes to pass to a third party.
Lack of control over data. Such a threat is partly addressed by explicitly highlighting the get alias request operation and then passing the attributes. Another measure that reduces the likelihood of such a threat is the passage of records through arbitrator nodes.
Unlawful collection of personal data (aggregated profiling). Addressing this threat is done through hiding quasi-identifiers throughout the identification process that is separate from creating profiles.
2.3.4 Data Privacy and Data Quality
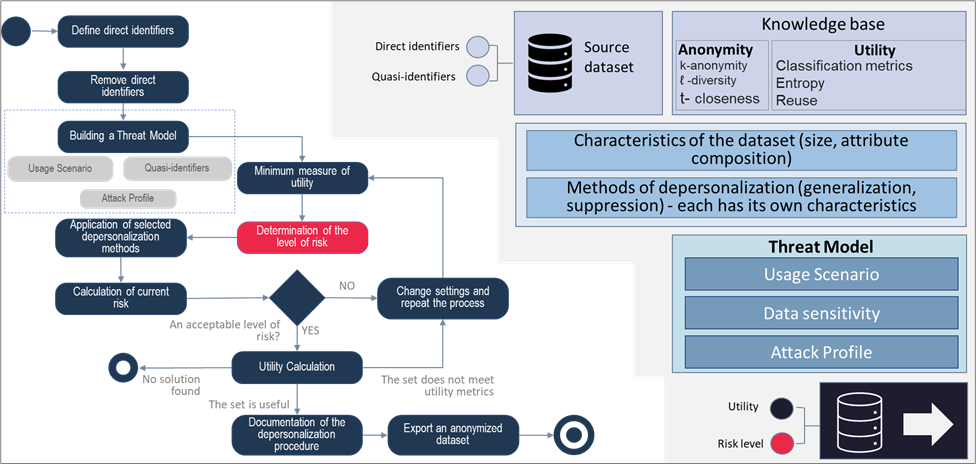
Within DGT, sensitive data is stored by notary nodes in specialized VCDB storages. At the same time, the threat/risk model of personal data (see 2.3.3) includes events in which part of the VCDB data may become available. To protect such data, an anonymization process is applied, which aims to reduce the risk of re-identification. Features of this process include:
Based on the quasi-identifiers selected for a given domain area, groups of similar data are distinguished within a data set. These groups are called equivalence classes. The number of entries within each class defines its cardinality, the class with the smallest cardinality is inversely proportional to the probability of reidentification. This concept is called k-anonymity.
Within the VCDB, the corresponding re-identification probability threshold is assumed as 10%, which means the minimum cardinality of the equivalence class is 10 entries.
To achieve this threshold, anonymization methods such as generalization and suppression are used.
In the process of processing by anonymization methods, data is destroyed, and its usefulness is reduced. The balance between the security of confidential data and its usefulness is a dynamic model that considers anonymization metrics on one side (such as k-anonymity and l-diversity), and utility metrics on the other (based on Shannon entropy metric or reuse metrics).
The general architecture of data anonymization is shown in the figure below.
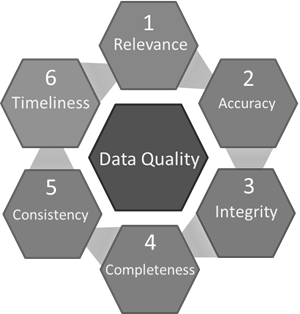
Data quality is an important parameter for the operation of the DGT platform. Data quality refers to a set of measurable metrics, the general composition of which is determined by several international standards, for example, ISO 9000:2015 (see figure below). On—chain data quality is determined by the consensus (see 2.3.1), which ensures data integrity and correctness. Similar assumptions apply to the quality of data that the off-chain notary nodes work with:
The quality of identification data is determined largely by utility and anonymization metrics.
The relevance of data largely depends on the SLA of the nodes and is ultimately linked to the minting mechanism, which allows the nodes of the network to participate in tokenization (see 2.7.1).
Footnotes