2.6 Data Model
2.6.1 Data layer overview
Transactions are the main part of the data storage model. Transactions are stored as batches inside blocks, on top of which a directed acyclic graph is built. Data is stored in the key-value database (using the Berkeley-DB like LMDB database) as well as in a specialized graph database. The source of the transactions are clients that are connected to the nodes via the API (each node has its own, in a general case - a typical API). Each transaction is a message composed of a body (transaction description) and a typical header that describes the purpose of the transaction, as well as for whom and to whom it is going.
Based on the results of the consensus mechanism (transaction verification), the transaction is asynchronously added to the DAG ledger, which is then synchronized across the network. When the transaction is added, its header is expanded through the addition of the hash of the transaction body, the digital signature of the node that is adding it, the hash of the previous transaction (or several transactions to which the current one is added), and the hash of the entire set of information (the totality of all transaction data, including voting results). Thus, DAG is a connected graph, the vertices of which are formed from the added transactions, while its edges are the links to previous transactions to which the current one is added (for complex transactions, such links to previous transactions are an arbitrary non-zero number that is greater or equal to one).
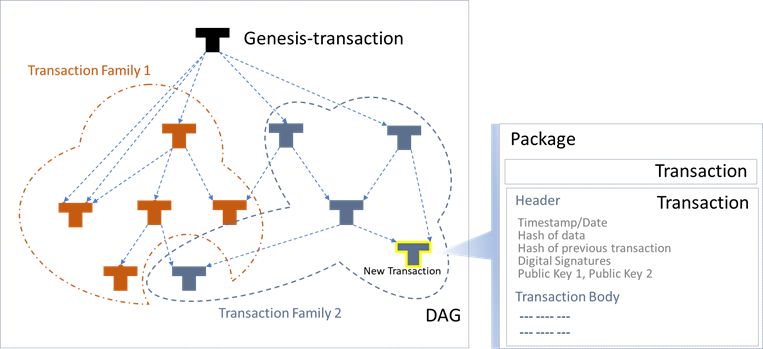
The DAG transaction ledger has the following properties:
Multiple transaction families are supported. Each is processed by a separate transaction processor. The transaction processor is a component that runs as a separate process and uses a specialized interface to communicate with the node core. Through this interface, the transaction processor receives transactions of a certain type for processing. The component is identified by name, version, and is registered within the validator core.
Ledger copies are located in each node and are synchronized across the network in a finite amount of time. Thus, data consistency is “eventually” implemented, while the transactions themselves are added asynchronously to the topologically sorted graph.
DAG copies are synchronized later, while the F-BFT Consensus guarantees no conflicts and no loss of dataset integrity. In fact, there is no full-scale ACID for the entire set, but the BASE (Basically Available, Soft-state, Eventually consistent) architecture is executed.
The graph grows asynchronously. At each moment of time, the growth is driven by its different branches in different topological nodes.
2.6.2 Genesis Record
The first entry in DAG contains setup and topology data and is formed differently than the rest according to a set procedure.
2.6.3 Sharding
Entries into the DAG are made in accordance with the specified reference points - graph growth vertices for individual types of transactions or clusters. This mechanism is called sharding. In this case, the graph is divided into segments (also called “shards” or “nests”) with which the corresponding cluster is working.
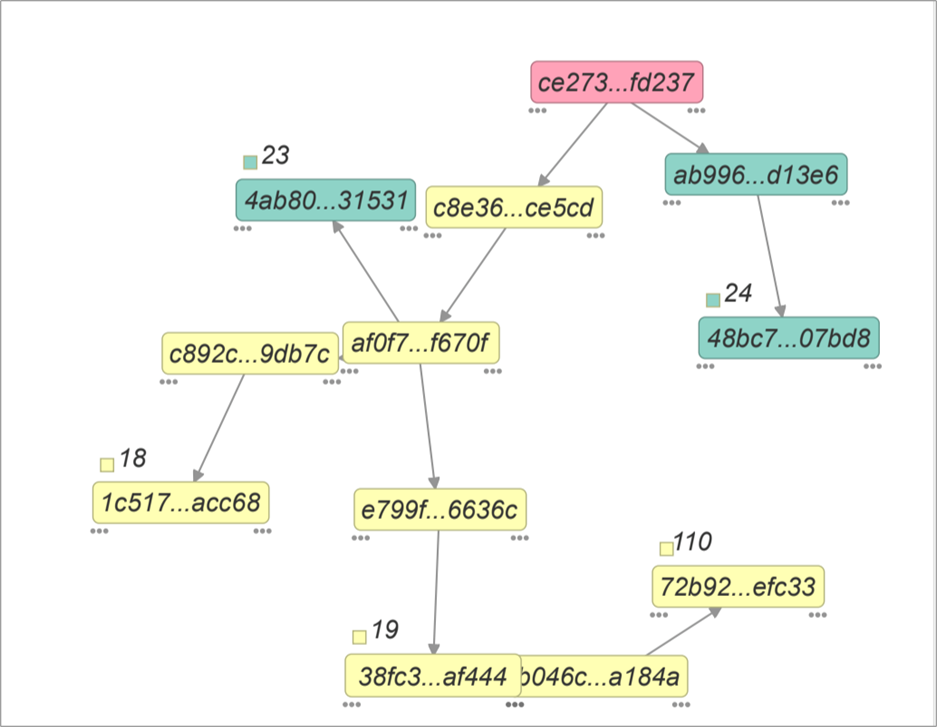
2.6.4 DAG Synchronization
As part of the work to synchronize DAG, the following modes are implemented through permalinks:
Incremental synchronization (updating transactions one by one as they are attached to an existing DAG)
Full update (downloading the entire database as a binary object) may be necessary when joining a node without a database to an already running cluster.